Text Annotation Tooling
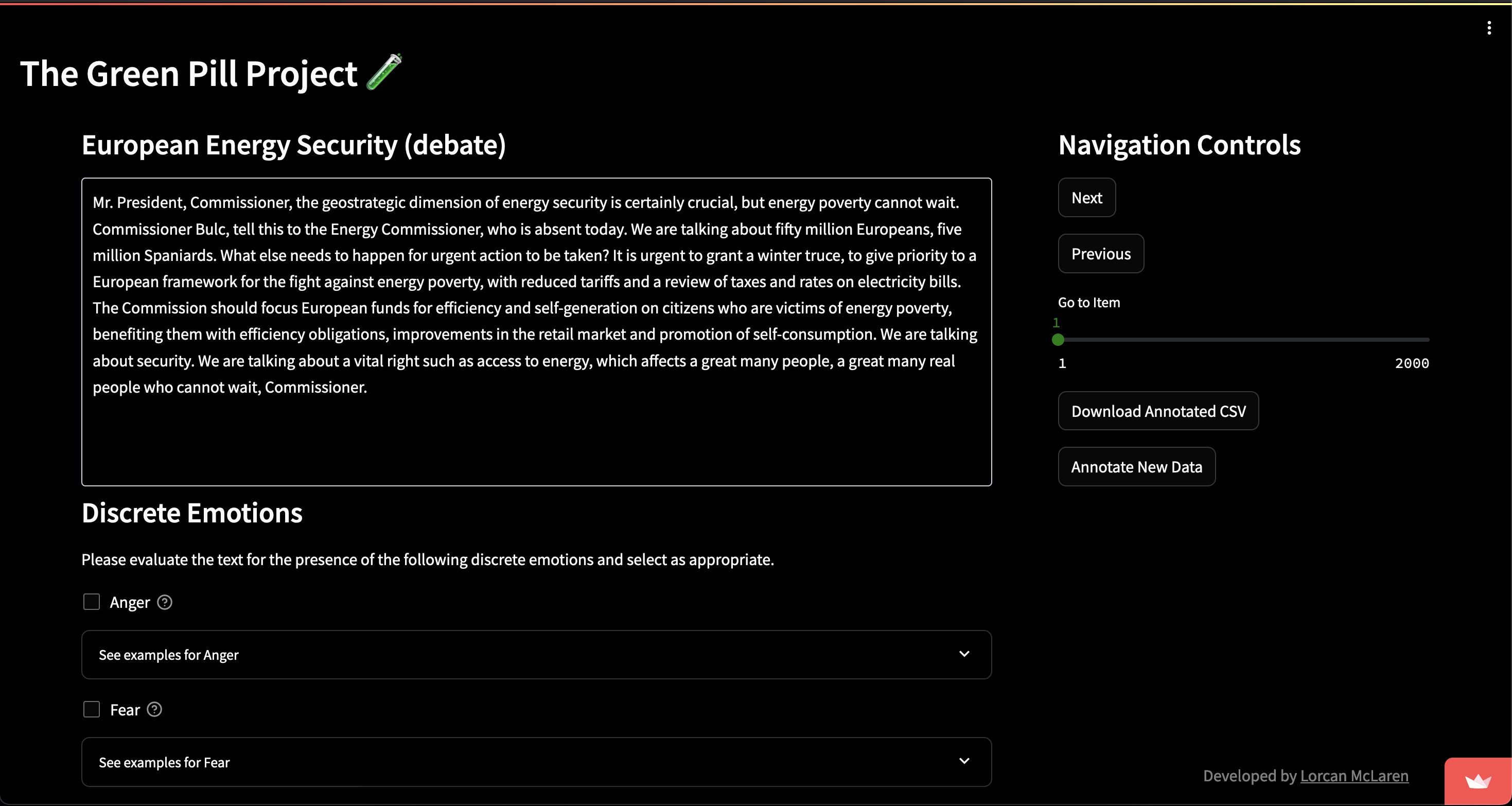
I am currently developing a customisable tool to provide an improved text annotation workflow to researchers. Creating large sets of annotated text is a common task in many text-as-data approaches. Recent advancements in LLMs have accelerated this trend, as domain-specific ground truth is important for validating zero- and few-shot models, or for fine-tuning.
My tool provides the following benefits at zero cost:
- Consistent experience for teams of annotators
- Low-latency, reproducible workflows
- Multiple common annotation types, including binary, dropdown or Likert scale
- Fully customisable, with functionality to develop your own annotation schema and instructions
- No more messy codebooks that force annotators to switch windows
- CSV input and output for interoperability
Try out a beta version of the tool here. Feel free to reach out if you encounter any bugs or need additional features for your annotation task